



Deep CNN Autoencoder for Image Compression & Denoising | Deep Learning | Python Tutorial
- Hackers Realm
- May 23, 2023
- 11 min read
Updated: May 31, 2023
An autoencoder is a type of unsupervised learning algorithm that aims to reconstruct its input data at the output layer, typically learns efficient data representations (encoding) by training the network to ignore signal “noise”. Autoencoders can be used for image denoising, image compression, data compression, anomaly detection, and feature extraction and, in some cases, even generation of image data.
A deep CNN autoencoder is a powerful approach for both image compression and denoising tasks. In this project tutorial we will explore how Deep CNN Autoencoder can be used for image compression and denoising.
In this project tutorial first we will see how autoencoder can be used for image compression
Deep CNN Autoencoder - Image Compression
For image compression, the deep CNN autoencoder learns to encode the important features of an input image into a compressed representation in the latent space. The encoding process reduces the dimensionality of the input image while retaining the essential information.

You can watch the video-based tutorial with a step-by-step explanation down below.
Flow of Autoencoder
Input Image -> Encoder -> Compressed Representation -> Decoder -> Reconstruct Input Image
The autoencoder takes an input data sample, here we have considered an image, and feeds it into the encoder network
The encoder network consists of several layers, typically including convolutional layers, pooling layers, and fully connected layers. These layers progressively reduce the spatial dimensions and extract meaningful features from the input data
The final layer of the encoder network produces a compressed representation of the input data
The compressed representation from the encoding stage is passed into the decoder network
The decoder network is symmetrical to the encoder network, consisting of fully connected layers, upsampling layers, and sometimes transposed convolutional layers. It takes the compressed representation and gradually increases the spatial dimensions to reconstruct the original input data
The final layer of the decoder network generates the reconstructed output, which aims to closely resemble the original input data
Import Modules
import numpy as np
import matplotlib.pyplot as plt
from keras import Sequential
from keras.layers import Dense, Conv2D, MaxPooling2D, UpSampling2D
from keras.datasets import mnistnumpy - used to perform a wide variety of mathematical operations on arrays
matplotlib - used for data visualization and graphical plotting
keras - used to provide a user-friendly and intuitive interface for designing, training, and evaluating deep learning models
keras.layers - provides a variety of pre-defined layers that can be used to construct neural network models
keras.datasets - provides pre-loaded datasets that can be used for training, testing, and evaluating machine learning models
Load the Dataset
The project uses The MNIST handwritten digits dataset
(x_train, _), (x_test, _) = mnist.load_data()mnist.load_data() loads the MNIST dataset
Preprocess the image Data
Next we will have to normalize the input image data
# normalize the image data
x_train = x_train.astype('float32') / 255
x_test = x_test.astype('float32') / 255astype('float32') converts the data type of the pixel values to float32. This step is performed to ensure compatibility with subsequent operations and to allow for decimal values
Then we will have to scale the pixel values by dividing them by 255. This step normalizes the pixel values to the range of 0 to 1, as the original pixel values are integers ranging from 0 to 255.
This normalization step is often applied to improve the training process and convergence of neural networks
Next we will reshape the input image data
# reshape in the input data for the model
x_train = x_train.reshape(len(x_train), 28, 28, 1)
x_test = x_test.reshape(len(x_test), 28, 28, 1)
x_test.shape(10000, 28, 28, 1)
reshape() is a NumPy function that reshapes the array
No of samples is 10000
(28,28,1) is the dimensions of the image , the first two dimensions represent the spatial dimensions (height and width), and the last dimension represents the number of channels
Exploratory Data Analysis
Here we will explore how the input image looks like
# randomly select input image
index = np.random.randint(len(x_test))
# plot the image
plt.imshow(x_test[index].reshape(28,28))
plt.gray()np.random.randint() generates a random integer index within the range of the length of the x_test array. This is used to randomly select an image from the test dataset
imshow() displays the image. It takes the reshaped image as input.
x_test[index] retrieves the image at the randomly generated index from the test dataset.
reshape() reshapes the selected image back to its original 2D shape of 28x28 pixels. This is necessary because the image was flattened into a 1D array when it was stored in x_test.
plt.gray() sets the color map of the plot to grayscale, so the image is displayed in black and white

This is the random image from the MNIST test dataset displayed using matplotlib, with the pixel values reshaped into a 2D grid and plotted in grayscale.
Next let us see one more images from the dataset
# randomly select input image
index = np.random.randint(len(x_test))
# plot the image
plt.imshow(x_test[index].reshape(28,28))
plt.gray()
This is another random image from the MNIST test dataset displayed using matplotlib, with the pixel values reshaped into a 2D grid and plotted in grayscale
Model Creation
Next we will define a sequential model in Keras for a convolutional autoencoder
model = Sequential([
# encoder network
Conv2D(32, 3, activation='relu', padding='same', input_shape=(28, 28, 1)),
MaxPooling2D(2, padding='same'),
Conv2D(16, 3, activation='relu', padding='same'),
MaxPooling2D(2, padding='same'),
# decoder network
Conv2D(16, 3, activation='relu', padding='same'),
UpSampling2D(2),
Conv2D(32, 3, activation='relu', padding='same'),
UpSampling2D(2),
# output layer
Conv2D(1, 3, activation='sigmoid', padding='same')
])
model.compile(optimizer='adam', loss='binary_crossentropy')
model.summary()Sequential([]) creates a new sequential model object
Inside the sequential model, a series of layers are added in order. The model architecture follows an encoder-decoder structure, typical of autoencoders
The encoder network consists of convolutional and pooling layers. The input shape of the first layer is specified as (28, 28, 1), indicating grayscale images of size 28x28 pixels
The decoder network consists of convolutional and upsampling layers
The final layer is the output layer, which uses a convolutional layer with a single channel and a sigmoid activation function to reconstruct the image
model.compile() compiles the model and configures the training process. The optimizer is set to 'adam', which is a popular optimization algorithm for neural networks. The loss function is set to 'binary_crossentropy', which is commonly used for binary classification problems
model.summary() prints a summary of the model architecture, including the number of parameters and the shape of each layer's output

This is the overview of the model's structure and parameter counts
Training the Model
Next we will train the model
# train the model
model.fit(x_train, x_train, epochs=20, batch_size=256, validation_data=(x_test, x_test))model.fit() is used to train the model
x_train is the input training data, and x_train is also used as the target output since it's an autoencoder (reconstructing the input)
epochs=20 specifies the number of times the entire training dataset will be iterated during training
batch_size=256 determines the number of samples used in each training update. In this case, 256 samples will be processed before updating the model's weights
validation_data=(x_test, x_test) is used to specify the validation data to evaluate the model's performance during training. Here, the same dataset (x_test) is used as both the input and target output
You will see the following result :

Visualize the results
First we will randomly select the image and display it
# randomly select input image
index = np.random.randint(len(x_test))
# plot the image
plt.imshow(x_test[index].reshape(28,28))
plt.gray()
This is the random image from the MNIST test dataset displayed using matplotlib
Next we will predict the results from model
# predict the results from model (get compressed images)
pred = model.predict(x_test)model.predict() is a method in Keras used to obtain predictions from a trained model
x_test is the input test data on which predictions will be made
Next we will visualize the compressed image obtained from model.predict()
# visualize compressed image
plt.imshow(pred[index].reshape(28,28))
plt.gray()
This is the compressed image . We can clearly see that there is some difference between original image and the compressed image
We can create subplots which will display the original and predicted compressed image side by side , which helps to visualize the difference between both the images clearly
index = np.random.randint(len(x_test))
plt.figure(figsize=(10, 4))
# display original image
ax = plt.subplot(1, 2, 1)
plt.imshow(x_test[index].reshape(28,28))
plt.gray()
ax.get_xaxis().set_visible(False)
ax.get_yaxis().set_visible(False)
# display compressed image
ax = plt.subplot(1, 2, 2)
plt.imshow(pred[index].reshape(28,28))
plt.gray()
ax.get_xaxis().set_visible(False)
ax.get_yaxis().set_visible(False)
plt.show()First, np.random.randint() as seen earlier generates a random integer index within the range of the length of the x_test array.
plt.figure() creates a new figure object with a specified size of 10 inches wide and 4 inches tall. This sets the overall size of the plot
plt.subplot(1, 2, 1) creates a subplot grid with 1 row and 2 columns and selects the first subplot for displaying the original image
plt.imshow() displays the original image at the selected index from x_test. The reshape(28, 28) is used to reshape the flattened image back to its original 2D shape of 28x28 pixels.
plt.gray() as seen earlier sets the color map of the plot to grayscale.
ax.get_xaxis().set_visible() and ax.get_yaxis().set_visible() hide the x-axis and y-axis ticks as we set False, respectively, to remove the axis labels
plt.subplot(1, 2, 2) selects the second subplot for displaying the compressed/reconstructed image.
Next we will display the reconstructed image at the selected index from pred using plt.imshow()
plt.show() displays the figure with both subplots showing the original and reconstructed images

This gives us better visualization where we can clearly see the difference between the original image and the predicted compressed image
We can check the results for one more image data to see the accuracy and performance of the model
index = np.random.randint(len(x_test))
plt.figure(figsize=(10, 4))
# display original image
ax = plt.subplot(1, 2, 1)
plt.imshow(x_test[index].reshape(28,28))
plt.gray()
ax.get_xaxis().set_visible(False)
ax.get_yaxis().set_visible(False)
# display compressed image
ax = plt.subplot(1, 2, 2)
plt.imshow(pred[index].reshape(28,28))
plt.gray()
ax.get_xaxis().set_visible(False)
ax.get_yaxis().set_visible(False)
plt.show()
This is one more example which shows the difference between the original image and the compressed image
Till now we have seen how autoencoders can be used for image compression. Next we will see how we can Denoise the image using autoencoders
Deep CNN Autoencoder - Denoising Image
The deep CNN autoencoder can be trained to remove noise from corrupted images. During the training process, the autoencoder is presented with pairs of clean and noisy images. The encoder network learns to extract meaningful features from the noisy images, while the decoder network reconstructs the clean version of the image from the encoded representation. By minimizing the difference between the reconstructed image and the clean image, the autoencoder learns to denoise the input images effectively.

You can watch the video-based tutorial with a step-by-step explanation down below.
Flow of Autoencoder
Noisy Image -> Encoder -> Compressed Representation -> Decoder -> Reconstruct Clear Image
The flow of the autoencoder is same as we have seen in the image compression , here instead of input image we will feed noisy image and at the end we will reconstruct clear image
Import Modules
import numpy as np
import matplotlib.pyplot as plt
from keras import Sequential
from keras.layers import Dense, Conv2D, MaxPooling2D, UpSampling2D
from keras.datasets import mnistWe will be using same modules for denoising the image that we have seen in image compression
Load the Dataset
Next we will load the dataset
(x_train, _), (x_test, _) = mnist.load_data()Preprocess the image Data
Next we will have to normalize the input image data
# normalize the image data
x_train = x_train.astype('float32') / 255
x_test = x_test.astype('float32') / 255This step normalizes the pixel values to the range of 0 to 1, as the original pixel values are integers ranging from 0 to 255.
This normalization step is often applied to improve the training process and convergence of neural networks
Next we will reshape the input image data
# reshape in the input data for the model
x_train = x_train.reshape(len(x_train), 28, 28, 1)
x_test = x_test.reshape(len(x_test), 28, 28, 1)
x_test.shape(10000, 28, 28, 1)
No of samples is 10000
(28,28,1) is the dimensions of the image , the first two dimensions represent the spatial dimensions (height and width), and the last dimension represents the number of channels
Add Noise to the Image
Next we will have to add random noise to training and testing images
# add noise
noise_factor = 0.6
x_train_noisy = x_train + noise_factor * np.random.normal(loc=0.0, scale=1.0, size=x_train.shape)
x_test_noisy = x_test + noise_factor * np.random.normal(loc=0.0, scale=1.0, size=x_test.shape)noise_factor is a scalar value that determines the intensity of the added noise. Higher values result in more pronounced noise
np.random.normal() generates random numbers from a normal distribution with a mean (loc) of 0.0 and a standard deviation (scale) of 1.0. The resulting array has the same shape as x_train or x_test
Next add the scaled random noise to the original x_train and x_test images, creating the noisy train and test set x_train_noisy and x_test_noisy respectively
Next we will limit the array values
# clip the values in the range of 0-1
x_train_noisy = np.clip(x_train_noisy, 0., 1.)
x_test_noisy = np.clip(x_test_noisy, 0., 1.)np.clip() applies element-wise clipping to the x_train_noisy array and x_test_noisy array, limiting the values to the range of 0 to 1. Any values below 0 are set to 0, and any values above 1 are set to 1. This ensures that the pixel values remain within the valid range for image data
Exploratory Data Analysis
Here we will explore how the input noisy images looks like
# randomly select input image
index = np.random.randint(len(x_test))
# plot the image
plt.imshow(x_test[index].reshape(28,28))
plt.gray()This displays random image from the test set using imshow() from matplotlib. The image will be shown in grayscale, with axis labels and color bar hidden by default. Each time the code is run, a different random image will be displayed due to the random selection of the index. This can be useful for visually inspecting individual images from the dataset.

This is the original image from the test dataset
Next we will display the same image with some noise
# randomly select input image
index = np.random.randint(len(x_test))
# plot the image
plt.imshow(x_test_noisy[index].reshape(28,28))
plt.gray()
We can clearly see that after adding noise it is hard identify the original image
Let us see some more images
# randomly select input image
index = np.random.randint(len(x_test))
# plot the image
plt.imshow(x_test_noisy[index].reshape(28,28))
plt.gray()
This is another noisy image from test dataset. By looking at this image it is hard to identify the original image
Let us see the original image
plt.imshow(x_test[index].reshape(28,28))
plt.gray()
Model Creation
Next we will define a sequential model in Keras for a convolutional autoencoder as we did during image compression
model = Sequential([
# encoder network
Conv2D(32, 3, activation='relu', padding='same', input_shape=(28, 28, 1)),
MaxPooling2D(2, padding='same'),
Conv2D(16, 3, activation='relu', padding='same'),
MaxPooling2D(2, padding='same'),
# decoder network
Conv2D(16, 3, activation='relu', padding='same'),
UpSampling2D(2),
Conv2D(32, 3, activation='relu', padding='same'),
UpSampling2D(2),
# output layer
Conv2D(1, 3, activation='sigmoid', padding='same')
])
model.compile(optimizer='adam', loss='binary_crossentropy')
model.summary()This is the overview of the model's structure and parameter counts
Training the model
Next we will train the model
# train the model
model.fit(x_train_noisy, x_train, epochs=20, batch_size=256, validation_data=(x_test_noisy, x_test))This trains the model for 20 epochs with a batch size of 256, using the x_train_noisy dataset as input and the x_train dataset as the target. The validation data is provided using the x_test_noisy dataset as input and the x_test dataset as the target
You will see the following result :

Visualize the results
First we will randomly select the image and display it
# randomly select input image
index = np.random.randint(len(x_test))
# plot the image
plt.imshow(x_test_noisy[index].reshape(28,28))
plt.gray()
This is the random noisy image from the MNIST test dataset displayed using matplotlib
Next we will predict the results from model
# predict the results from model (get compressed images)
pred = model.predict(x_test_noisy)x_test_noisy is the input test data on which predictions will be made
Next we will visualize the denoised image obtained from model.predict()
# visualize compressed image
plt.imshow(pred[index].reshape(28,28))
plt.gray()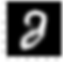
This is the denoised image . We can clearly see that the noise in the image has been removed and we have got a better image
We can create subplots which will display the original and predicted denoised image side by side , which helps to visualize the difference between both the images clearly
index = np.random.randint(len(x_test))
plt.figure(figsize=(10, 4))
# display original image
ax = plt.subplot(1, 2, 1)
plt.imshow(x_test_noisy[index].reshape(28,28))
plt.gray()
ax.get_xaxis().set_visible(False)
ax.get_yaxis().set_visible(False)
# display compressed image
ax = plt.subplot(1, 2, 2)
plt.imshow(pred[index].reshape(28,28))
plt.gray()
ax.get_xaxis().set_visible(False)
ax.get_yaxis().set_visible(False)
plt.show()The above code snippet displays a comparison between an original image and its reconstructed (compressed) version
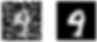
This gives us better visualization where we can clearly see the difference between the original image and the predicted denoised image
We can check the results for one more image data to see the accuracy and performance of the model
index = np.random.randint(len(x_test))
plt.figure(figsize=(10, 4))
# display original image
ax = plt.subplot(1, 2, 1)
plt.imshow(x_test_noisy[index].reshape(28,28))
plt.gray()
ax.get_xaxis().set_visible(False)
ax.get_yaxis().set_visible(False)
# display compressed image
ax = plt.subplot(1, 2, 2)
plt.imshow(pred[index].reshape(28,28))
plt.gray()
ax.get_xaxis().set_visible(False)
ax.get_yaxis().set_visible(False)
plt.show()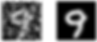
This is one more example which shows the difference between the original image and the denoised image
Final Thoughts
A deep CNN autoencoder combines the power of CNNs for spatial feature extraction and the reconstruction capabilities of autoencoders to learn efficient representations of input data. It can be used for various applications where learning compact and meaningful representations is essential. Here we have seen the application of autoencoder for image compression and denoising
The advantage of using a deep CNN in the autoencoder architecture for image compression is that it can capture spatial dependencies and extract meaningful features from the input image. The convolutional layers in the encoder network perform local feature extraction, capturing fine details and patterns. The decoder network uses transposed convolutional layers to upsample the compressed representation and reconstruct the image with improved resolution. The deep CNN architecture helps preserve important image features during compression and ensures higher-quality reconstruction compared to traditional methods
Similar to image compression, the deep CNN architecture in the autoencoder is advantageous for image denoising as it can capture complex spatial patterns and extract hierarchical features. The convolutional layers in the network can identify noise patterns and suppress them, allowing the decoder network to reconstruct a cleaner version of the image
In summary, a deep CNN autoencoder is a powerful approach for both image compression and denoising tasks. It can learn efficient representations of images in the latent space, allowing for image compression with reduced memory or bandwidth requirements. Additionally, it can effectively remove noise from corrupted images, resulting in cleaner and higher-quality reconstructions
In this project tutorial, we have explored how Deep CNN Autoencoder can be used for image compression and denoising
Get the project notebook from here
Thanks for reading the article!!!
Check out more project videos from the YouTube channel Hackers Realm